Threat modelling this (old) website
My previous post looked at producing a C4 model for my (simple) website. This post takes that a step further and looks at how we can use C4 modelling to elicit security and privacy threats using two frameworks:
- STRIDE. Most people know STRIDE, it’s derived from the Microsoft security threat modelling process from the early 2000s and represents Spoofing, Tampering, Repudiation, Information leakage, Denial of service and Elevation of privilege.
- LINDDUN. This is not so widely known but I first came across it in one of the Application Security Podcasts on Privacy Threat Modelling. “LINDDUN was created in 2010 as a collaboration between the DistriNet and COSIC research groups of KU Leuven, Belgium”. It is a framework, not unlike STRIDE, which represents Linkability, Identifiability, Non-repudiation, Detectability, Disclosure of information, Unawareness and Non-compliance.
However, both STRIDE and LINDDUN base themselves around classical threat modelling techniques which, in my opinion, are somewhat old school and result in the generation of diagrams which are unrepresentative of real world applications, become unmaintainable very quickly and are difficult to read; these diagrams are called Data Flow Diagrams (DFDs) and, IMO, should be used with caution for the reasons above.
Next on the modification list was LINDDUN. It’s a well developed technique that’s a good few years old but seems to have a lot of cross over with STRIDE. Mapping the two frameworks together and seeing how applicable LINDDUN is, I found that:
- Linkability - useful, although there is a lot of crossover with Identifiability and it was very confusing initially to think about how to apply it. However, I have incorporated it.
- Identifiability - very useful, this was incorporated without question.
- Non-repudiation - this was already covered by R in STRIDE so wasn’t incorporated.
- Detectability - I incorporated this and saw it as useful at the front end.
- Disclosure of info - I felt this was already covered by the I in STRIDE so didn’t incorporate it.
- Unawareness - I felt that this was very much focussed on entities (specifically users) and incorporated it.
- Non-compliance - I felt that this was an emergent property of any of the above elements not being mitigated and was almost a super-set issue as opposed to something that could be added specifically to components on our threat model. Hence I did not incorporate it.
In summary, I got that down to:
LIDU
or, in an ideal world of merging it with STRIDE:
STRIDELIDU
Threat modelling this website⌗
Rapid Threat Modelling techniques, as advocated by Geoff Hill and is an approach that I very much advocate. The premise behind it is that you base the entirety of the threat modelling process around diagrams that teams should already be producing as a part of their design processes. Having a diagram that is representative of the architecture of the system being deployed and which is maintained by the necessity of it being a part of an operational runbook means that it is always kept up to date. If threat modelling then becomes metadata on top of the diagram, the threat modelling process is therefore also kept up to date as the core architecture changes over time - win win!
Let’s go back to the C4 diagram from the previous post:
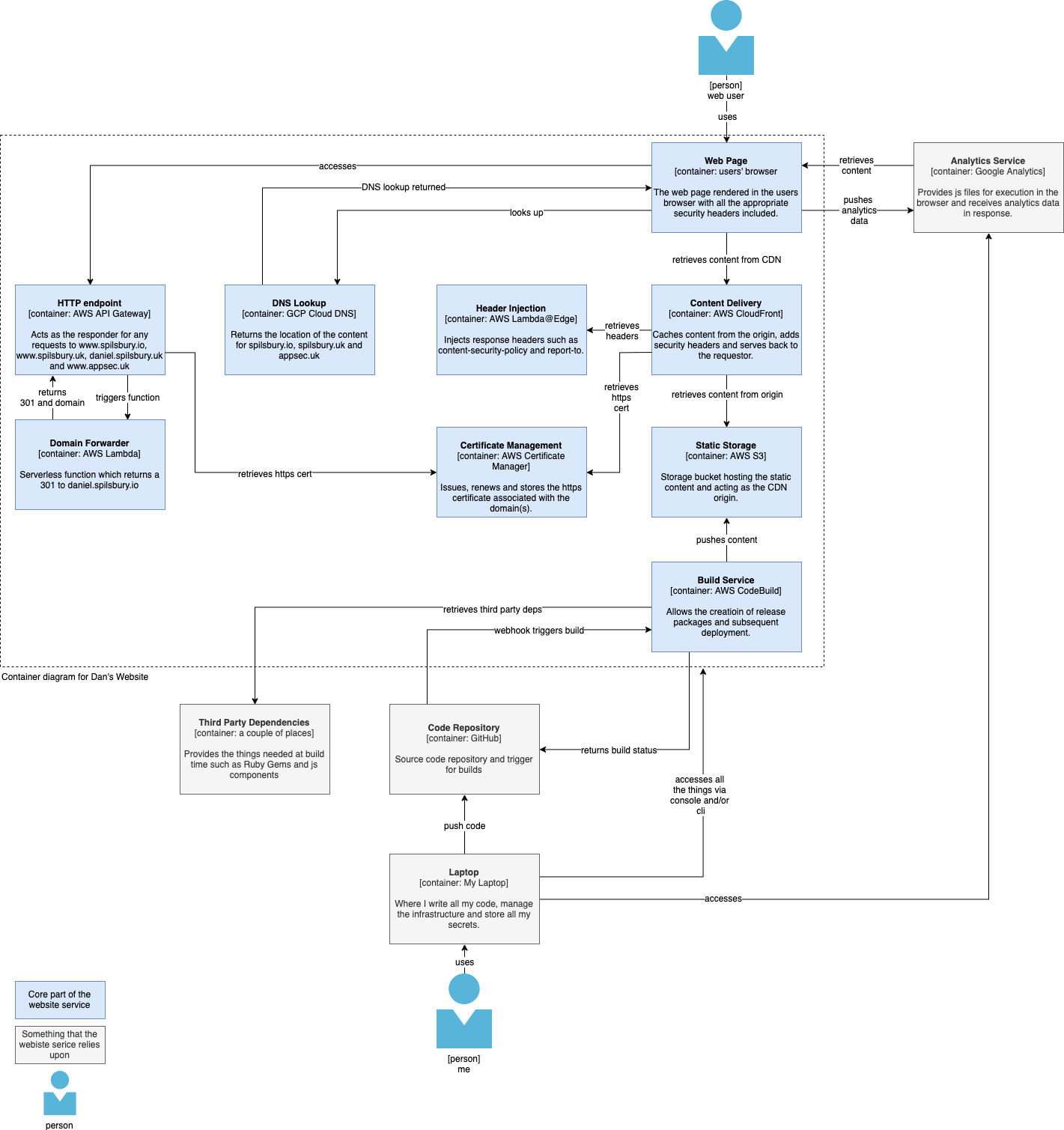
And let’s now overlay that diagram with some threat modelling metadata which is made up of three components:
- STRIDE & LIDU. STRIDE and LIDU are described above and are applied to each component (and connection) on the diagram. I’ve not added them to each connection on purpose as I know that all my connections, apart from DNS, are over secure channels e.g. TLS or SSH.
- Trust:Value Ratio. Classically, threat modelling teaches us to apply trust zones to diagrams. In the many threat modelling sessions that I’ve been involved with, I’ve repeatedly found that they don’t do it justice, hence now using an extension of that called Trust:Value Ratios. The trust component is exactly what you’re used to with trust zone numbering. The value component is the value of the data that exists in that location. An example is a trust:value ratio of 1:2; the trust zone is 1, such as a users’ browser, but the value of the data processed there is 2, such as authentication tokens or sensitive data.
- Aggregated Risks. This is a leap of faith; you need to have learned how to do risk assessment using threat modelling before you can use aggregated risks but they appear on the diagram as purple circles with numbers in the centre. They are a leap of faith because my experience in threat modelling allows me to quickly spot the key risks that a product presents through the threat model, and those are what I document as aggregated risks.
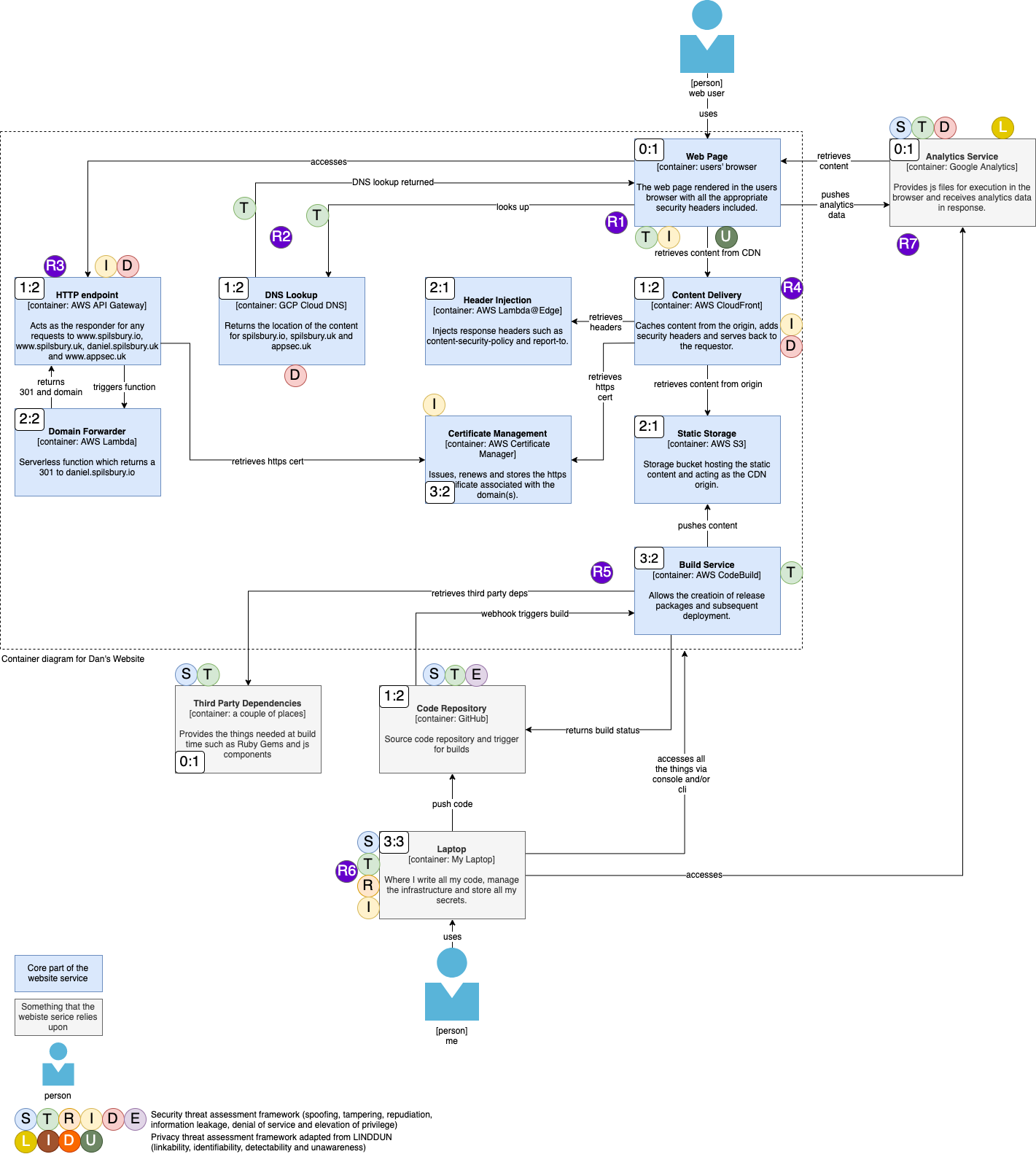
We now have seven aggregated risks which we can expand on as follows:
| Risk | Description | How much do I care (think P:I) |
|---|---|---|
| R1 | The webpage is rendered in the users browser which is an untrusted environment. Other malicious code could be executed in that same environment and interfere with or steal data from my application. | Not really, I don’t want crypto miners running in user space so I’ll use CSP to prevent that. |
| R2 | DNS sucks, it is in the clear and could be spoofed/modified so that a user is directed to a malicious endpoint. | This would suck too but it’s kinda in the hands of the user to ensure they use good DNS practices e.g. DoT/H. However, I do use DS signing on my domain so if you check DNSSEC records then that will help. |
| R3 | The HTTP endpoint could be subject to volumetric based attacks which take it down, but, more importantly, cost me dollar! | I do care about the latter issue so have alerting in place and request limitations. |
| R4 | My website is served from a CDN which could be subject to volumetric based attacks which take it down or cost me cash. | As for R3. |
| R5 | The build service pulls a bunch of third party deps when it builds my site. Any one of these could contain malicious code which I could end up serving to users. | My lock files specify known versions and I have GitHub Security Alerts switched on to look for vulnerabilities in my dependencies. |
| R6 | If I lose my laptop, all my access keys and passwords go with it so my entire site could be taken out. | This comes down to OPSec; having good security practices in place around how my device is built and how I handle it mitigate this. |
| R7 | There are a couple of risks here, one around the loading of third party scripts at page load and secondly because google hoover up a boat load of analytics data about a user. | The first I will mitigate by self hosting the script for GA. The second, as highlighted by the ‘U’ on the web page component, means I need to make sure users are informed about the use of GA. |
And that’s it - we have a threat model which is based on an architecture diagram that should be maintained and doesn’t take rocket science to build.